- 由於網址中發現post所送出的資料,改用get試看看!
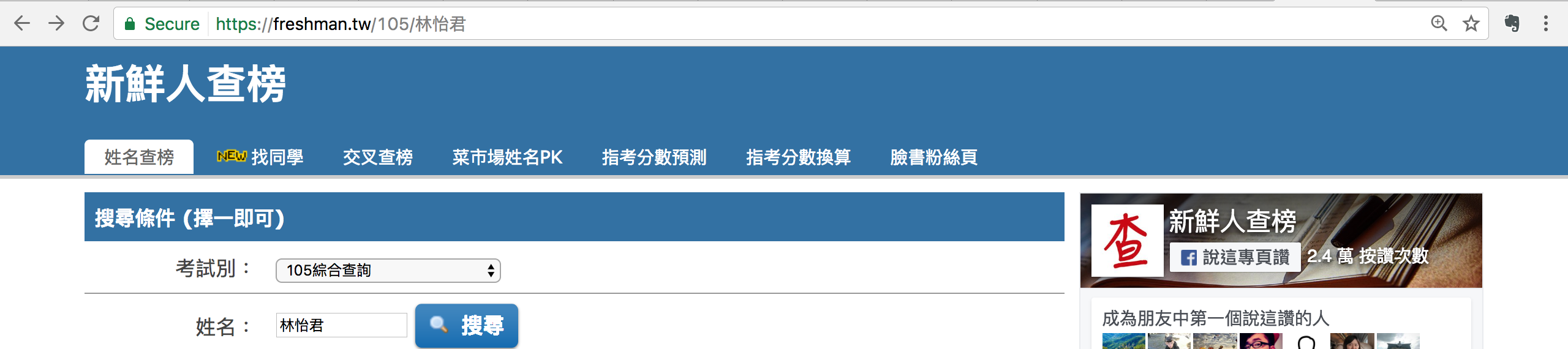
import requests
url = 'https://freshman.tw/105/林怡君'
request_headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) ' \
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
}
r = requests.get(url, headers=request_headers)
if '10044331' in r.text:
print('got!')
- BeautifulSoup第一個參數為文字資料,第二個參數為parser名稱,一般用預設parser "lxml"
- 先產生BeautifulSoup物件,存入變數soup, 再用soup擷取資料
- 用DevTools觀察標籤
- select方法用來選取指定的標籤
- "tr.showPhoto"代表目標為「有"showPhoto" class的tr標籤」
- select方法回傳一個「標籤list」,如擷取不到任何資料,則回傳一個「空list」
from bs4 import BeautifulSoup as bs
soup = bs(r.text, 'lxml')
tags = soup.select('tr.showPhoto')
print(type(tags))
- 空list "examinees"用來存所有考生資料
- 將標籤list放入for迴圈,一次處理一個tr標籤
- 再觀察標籤,以select方法分別取出各欄位,先存入暫存字典,再將每個字典附加至examinees
examinees = []
for t in tags:
dic = {
'id_no':t.select('td')[0].text,
'name':t.select('td')[2].text,
'school':t.select('td')[3].text,
'dept':t.select('td')[4].text,
'identity':t.select('td')[5].text,
}
examinees.append(dic)
print(dic)
- examinees的型態已是「包含字典的list」,可只接以panda表格顯示
import pandas
df = pandas.DataFrame(examinees)
df
- 練習:交叉查榜
- 仿照本範例
- 將每個"001 國立臺灣大學"的"001當作key, "國立臺灣大學"當作value, 存入暫存字典
- 再將每個字典附加至list "schools"
- 最後以pandas表格顯示,會是個對角矩陣(diagonal matrix)
- 提示:會用到str.split()處理"001 國立臺灣大學"